В настоящее время оптическое распознавание символов является предпочтительным способом оцифровки документов вместо того, чтобы вводить метаданные документов вручную, потому что OCR идентифицирует текст в документах, которые подаются в систему управления документами, и позволяет вам что-то делать с простой текст, даже не читая его самостоятельно. Для JavaScript есть популярное решение на основе механизма распознавания текста Tesseract, о котором мы говорим проект Tesseract.js. Tesseract.js — это чистый Javascript-порт популярного механизма распознавания текста Tesseract. Эта библиотека поддерживает более 60 языков, автоматическую ориентацию текста и обнаружение сценариев, простой интерфейс для чтения абзацев, слов и рамок, ограничивающих символы. Tesseract.js может работать как в браузере, так и на сервере с NodeJS, что делает его доступным на многих платформах.
В этой статье мы покажем, как использовать Tesseract.js в браузере для преобразования изображения в текст (извлечение текста из изображения).
1. Установка Tesseract.js
Как уже упоминалось, вы можете использовать библиотеку Tesseract.js из браузера, используя CDN или локальную копию (для получения дополнительной информации об этой библиотеке, пожалуйста, посетите официальный репозиторий на Github здесь). Tesseract.js работает следующим образом, вам понадобятся 2 сценария, а именно tesseract.js и его tesseract-worker.js. Как и ожидалось, для достижения приемлемой производительности в браузере скрипт использует веб-работника, который находится в другом файле (tesseract-worker.js), что означает, что вам нужно только включить tesseract.js и работник должен находиться в том же каталоге, что и сценарий автоматически включит работника для вас.
A.1. Быстрый и простой способ
Используя бесплатный CDN, вы можете включить в документ только сценарий tesseract, который будет автоматически включать работника в фоновом режиме:
Он также автоматически загрузит обученные данные для языка, который вам нужен, из CDN (что вам нужно сделать самостоятельно, если вы хотите разместить локальную копию). После включения этого простого скрипта вы будете готовы использовать tesseract, поэтому выполните шаг 2.
А.2. Из локальной копии
Если использование CDN не подходит для вас, вы хотите иметь локальную копию сценария на своем собственном сервере. Первое, что вам нужно знать, это то, что вам нужно скачать первичные 2 сценария работника Tesseract и индексный скрипт:
- index.js (которую можно получить из репозитория tesseract.js-core, а именно из файла index.js)
- worker.js
После того, как вы поместите их в какую-то папку, вам понадобятся также некоторые языковые данные (по крайней мере, те, которые вы хотите использовать), которые будут храниться в некоторой папке, которая будет содержать все языки, которые вам нужно добавить в Tesseract, вам нужно укажите путь к этой папке во время инициализации Tesseract:
// After including the Tesseract script, initialize it in the browser
window.Tesseract = Tesseract.create({
// Path to worker
workerPath: '/worker.js',
// Path of folder where the language trained data is located
langPath: '/langs-folder/',
// Path to index script of the tesseract core ! https://github.com/naptha/tesseract.js-core
corePath: '/index.js',
});Скрипты Tesseract используют простой шаблон langPath + langCode + '.traineddata.gz' чтобы загрузить правильные обученные данные языка, который нужен сценарию. Вы можете получить эти данные, используя код языка ISO 639-2 / T или ISO 639-2 / B (3-значный код) и загрузку файла из CDN, например, для загрузки данных на английском и испанском языках (Вы можете получить файл из репозитория tessdata здесь):
// Download the spanish trained data
https://cdn.rawgit.com/naptha/tessdata/gh-pages/3.02/spa.traineddata.gz
// Download the english trained data
https://cdn.rawgit.com/naptha/tessdata/gh-pages/3.02/eng.traineddata.gzВ предыдущем примере и с использованием только 2 языков структура нашей папки выглядит следующим образом:
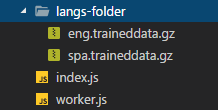
Помните, что скрипт загружает обученные данные, которые ему нужны (не все одновременно, если вы этого не хотите). Размер файла обычно не составляет пару КБ, но не менее 800 КБ (например, пакет на английском языке весит 9 МБ).
2. Распознавание текста по изображению
После правильного включения библиотеки вы сможете преобразовать изображение в текст, используя Tesseract.recognize Метод, который предлагает в основном интерфейс Promise и работает следующим образом. Метод выясняет, какие слова в imageгде слова в image, так далее.
Заметка
image должно быть достаточно высокое разрешение. Часто одно и то же изображение получит гораздо лучшие результаты, если вы увеличите его до вызова recognize,
imageлюбой ImageLike объект. Основные функции Tesseract.js принимаютimageпараметр, который должен быть чем-то похожим на изображение. То, что считается «подобным изображению», отличается в зависимости от того, запускается ли оно из браузера или через NodeJS.В браузере изображение может быть:
-
img,video, или жеcanvasэлемент - CanvasRenderingContext2D (возвращается
canvas.getContext('2d')) -
Fileобъект (из файлаили событие перетаскивания) -
Blobобъект -
ImageDataэкземпляр (объект, содержащийwidth,heightа такжеdataсвойства) - путь или URL-адрес доступного изображения (изображение должно быть размещено локально или доступно в CORS)
В Node.js изображение может быть
- путь к локальному образу
-
Bufferэкземпляр, содержащийPNGили жеJPEGобраз -
ImageDataэкземпляр (объект, содержащийwidth,heightа такжеdataсвойства)
-
optionsлибо отсутствует (в этом случае это интерпретируется как'eng'), строка, указывающая краткий код языка из список языков, или плоский объект JSON, который может:- включить свойства, которые переопределяют некоторое подмножество параметры по умолчанию
- включить
langсвойство со значением из список параметров языка
Метод возвращает TesseractJob чья then, progress, catch а также finally методы могут использоваться для воздействия на результат, поэтому вы можете сохранить его в переменной и вызвать некоторые методы в соответствии с вашими потребностями. В следующем примере показано, как распознать английские слова из изображения с использованием локальных ресурсов и базовой инициализации (код готов к тестированию, просто измените путь к файлам в вашем проекте, изображение и все):
Tesseract Example
Convert image to text
// 1. After including the Tesseract script, initialize it in the browser
// Note: to prevent problems while tesseract loads scripts, provide the absolute path to the file from your domain
window.Tesseract = Tesseract.create({
// Path to worker
workerPath: 'http://mydomain.com/worker.js',
// Path of folder where the language trained data is located
// note the "/" at the end, this string will be concatenated with the selected language
langPath: 'http://mydomain.com/langs-folder/',
// Path to index script of the tesseract core ! https://github.com/naptha/tesseract.js-core
corePath: 'http://mydomain.com/index.js',
});
// 2. Write some logic to initialize the text recognition
document.getElementById("img-to-txt").addEventListener("click", function(){
let btn = this;
// Disable button until the text recognition finishes
btn.disable = true;
// Convert an image to text. This task works asynchronously, so you may show
// your user a loading dialog or something like that, or show the progress with Tesseract
Tesseract.recognize("./text.png").then(function(result){
// The result object of a text recognition contains detailed data about all the text
// recognized in the image, words are grouped by arrays etc
console.log(result);
// Show recognized text in the browser !
alert(result.text);
}).finally(function(){
// Enable button once the text recognition finishes (either if fails or not)
btn.disable = false;
});
}, false);
Однако не каждый текст в мире написан на английском языке, поэтому вы можете настроить его на использование предварительно обученных данных с другого языка, если у вас есть пакет. Например, с испанского:
Tesseract Example
Convert image to text
// 1. After including the Tesseract script, initialize it in the browser
// Note: to prevent problems while tesseract loads scripts, provide the absolute path to the file from your domain
window.Tesseract = Tesseract.create({
// Path to worker
workerPath: 'http://mydomain.com/worker.js',
// Path of folder where the language trained data is located
// note the "/" at the end, this string will be concatenated with the selected language
langPath: 'http://mydomain.com/langs-folder/',
// Path to index script of the tesseract core ! https://github.com/naptha/tesseract.js-core
corePath: 'http://mydomain.com/index.js',
});
// 2. Write some logic to initialize the text recognition
document.getElementById("img-to-txt").addEventListener("click", function(){
let btn = this;
// Disable button until the text recognition finishes
btn.disable = true;
// Configure recognition
let tesseractSettings = {
lang: 'spa'
};
// Convert an image to text. This task works asynchronously, so you may show
// your user a loading dialog or something like that, or show the progress with Tesseract
Tesseract.recognize("./texto.png", tesseractSettings).then(function(result){
// The result object of a text recognition contains detailed data about all the text
// recognized in the image, words are grouped by arrays etc
console.log(result);
// Show recognized text in the browser !
alert(result.text);
}).finally(function(){
// Enable button once the text recognition finishes (either if fails or not)
btn.disable = false;
});
}, false);
В этой статье мы рассмотрели основную необходимость извлечения текста из изображения. Библиотека предлагает больше утилит, таких как отображение прогресса распознавания, выяснение того, какой сценарий использует изображение, например. «Латинский», «китайский». Так что не стесняйтесь при посещении официальный репозиторий на Github здесь открыть для себя более полезные методы.