Содержание
отказ
Ни при каких обстоятельствах мы (Наш Кодовый Мир) или разработчик этого модуля не несем ответственности за прямые, косвенные, специальные или другие косвенные убытки, возникшие в результате использования этого модуля или с веб-страниц, загруженных с этим модулем. Используйте его на свой страх и риск.
И с нашей оговоркой мы не говорим о том, что ваш компьютер взорвется с помощью модуля, который мы будем использовать для копирования веб-сайта. Мы только предупреждаем, что этот сценарий не следует использовать для незаконных действий (например, подделка веб-сайта и показ его в другом веб-домене), но для получения дополнительной информации о Node.js и веб-разработке.
Сказав это, вы когда-нибудь видели удивительный веб-сайт с каким-то потрясающим гаджетом или виджетом, который вы абсолютно хотите иметь или узнаете, как это сделать, но вы не находите библиотеку с открытым исходным кодом, которая делает это? Потому что в качестве первого шага, это то, что нужно сделать в первую очередь, найдите библиотеку с открытым исходным кодом, которая создает этот потрясающий гаджет, и, если он существует, внедрите его в свой собственный проект. Если вы его не найдете, то вы можете использовать инструменты разработчика Chrome, чтобы осмотреть элемент и поверхностно увидеть, как он работает и как вы можете создать его самостоятельно. Однако, если вам не так повезло или у вас нет навыков, чтобы скопировать функцию с помощью инструментов разработчика, у вас все еще есть возможность сделать это.

Что может быть лучше, чем иметь весь код, который создает потрясающий виджет и редактировать его, как вы хотите (вещь, которая поможет вам понять, как работает виджет). Именно об этом вы узнаете в этой статье, как загрузить весь веб-сайт через его URL с помощью Node.js с помощью веб-скребка. Web Scraping (также называемый Screen Scraping, Web Data Extraction, Web Harvesting и т. Д.) — это метод, используемый для извлечения больших объемов данных с веб-сайтов, посредством которого данные извлекаются и сохраняются в локальном файле на вашем компьютере или в базе данных в таблице (электронная таблица). ) формат.
Требования
Для загрузки всех ресурсов с сайта мы будем использовать модуль сайта-скребка. Этот модуль позволяет загружать весь веб-сайт (или отдельные веб-страницы) в локальный каталог (включая все ресурсы css, images, js, шрифты и т. Д.).
Установите модуль в своем проекте, выполнив следующую команду в терминале:
npm install website-scraperЗаметка
Динамические веб-сайты (где контент загружается с помощью js) могут сохраняться некорректно, так как website-scraper не выполняет js, он только анализирует ответы http для файлов html и css.
Посетить Официальный репозиторий Github для получения дополнительной информации здесь.
1. Скачать одну страницу
Функция scrape возвращает Promise, который отправляет запросы на все предоставленные URL-адреса и сохраняет все файлы, найденные в исходных кодах, в каталог. Ресурсы будут организованы в папки в соответствии с типом ресурсов (CSS, изображения или сценарии) внутри предоставленного пути к каталогу. Следующий скрипт загрузит домашнюю страницу сайта node.js:
const scrape = require('website-scraper');
let options = {
urls: ['https://nodejs.org/'],
directory: './node-homepage',
};
scrape(options).then((result) => {
console.log("Website succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});Сохраните предыдущий скрипт в js-файле (script.js) и затем выполните его с узлом, используя node index.js, После завершения сценария содержимое node-homepage папка будет:
И index.html Файл из веб-браузера будет выглядеть так:
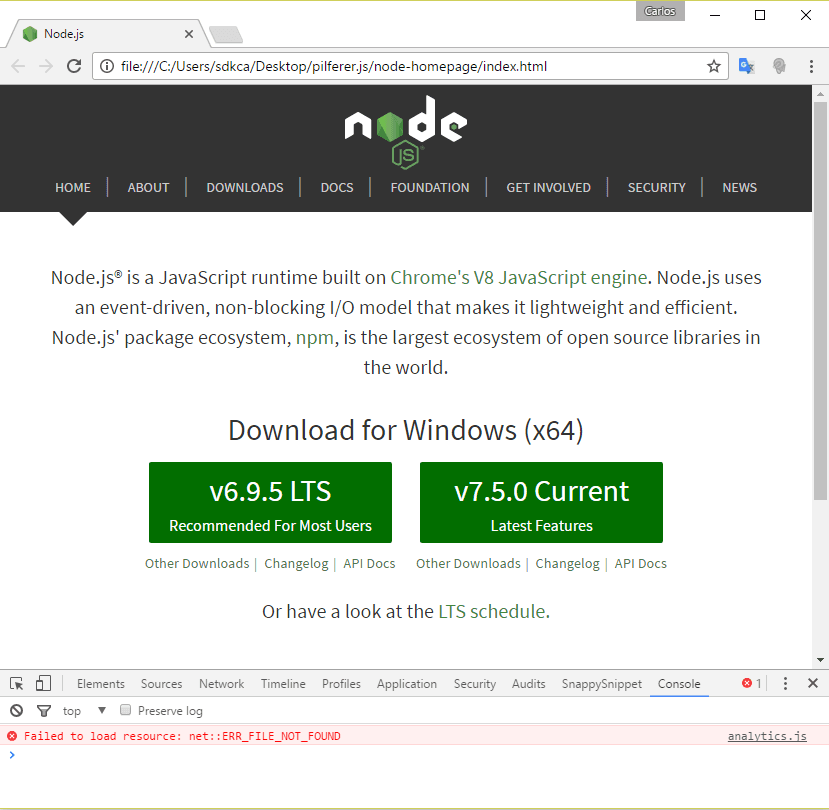
Все скрипты, таблицы стилей были загружены, и сайт работает как шарм. Обратите внимание, что единственная ошибка, отображаемая в консоли, связана со сценарием аналитики от Google, который вы, очевидно, должны удалить из кода вручную.
2. Скачать несколько страниц
Если вы загружаете несколько страниц веб-сайта, вы должны предоставить их одновременно в одном и том же сценарии, скребок достаточно умен, чтобы знать, что ресурс не следует загружать дважды (но только если ресурс уже был загружен с того же веб-сайта). на другой странице), и он загрузит все файлы разметки, но не ресурсы, которые уже существуют.
В этом примере мы собираемся загрузить 3 страницы веб-сайта node.js (index, about и blog), указанного в urls имущество. Содержимое будет сохранено в папке узла-сайта (где выполняется скрипт), если оно не существует, оно будет создано. Чтобы быть более организованным, мы собираемся отсортировать ресурсы каждого типа вручную в разных папках соответственно (изображения, javascript, css и шрифты). Свойство sources указывает массив загружаемых объектов, указывает селекторы и значения атрибутов для выбора файлов для загрузки.
Этот скрипт полезен, если вы хотите использовать некоторые веб-страницы:
const scrape = require('website-scraper');
scrape({
urls: [
'https://nodejs.org/', // Will be saved with default filename 'index.html'
{
url: 'http://nodejs.org/about',
filename: 'about.html'
},
{
url: 'http://blog.nodejs.org/',
filename: 'blog.html'
}
],
directory: './node-website',
subdirectories: [
{
directory: 'img',
extensions: ['.jpg', '.png', '.svg']
},
{
directory: 'js',
extensions: ['.js']
},
{
directory: 'css',
extensions: ['.css']
},
{
directory: 'fonts',
extensions: ['.woff','.ttf']
}
],
sources: [
{
selector: 'img',
attr: 'src'
},
{
selector: 'link[rel="stylesheet"]',
attr: 'href'
},
{
selector: 'script',
attr: 'src'
}
]
}).then(function (result) {
// Outputs HTML
// console.log(result);
console.log("Content succesfully downloaded");
}).catch(function (err) {
console.log(err);
});3. Рекурсивные загрузки
Представьте, что вам нужны не только определенные веб-страницы с веб-сайта, но и все его страницы. Один из способов сделать это — использовать предыдущий скрипт и указать вручную каждый URL-адрес веб-сайта, который вы можете загрузить, однако это может привести к обратным результатам, поскольку это займет много времени и, возможно, вы пропустите некоторые URL-адреса. Вот почему Scraper предлагает функцию рекурсивной загрузки, которая позволяет вам переходить по всем ссылкам со страницы, ссылкам с этой страницы и так далее. Очевидно, что это приведет к очень очень длинному (и почти бесконечному) циклу, который вы можете ограничить максимально допустимой глубиной (maxDepth имущество):
const scrape = require('website-scraper');
let options = {
urls: ['https://nodejs.org/'],
directory: './node-homepage',
// Enable recursive download
recursive: true,
// Follow only the links from the first page (index)
// then the links from other pages won't be followed
maxDepth: 1
};
scrape(options).then((result) => {
console.log("Webpages succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});Предыдущий скрипт должен загрузить больше страниц:
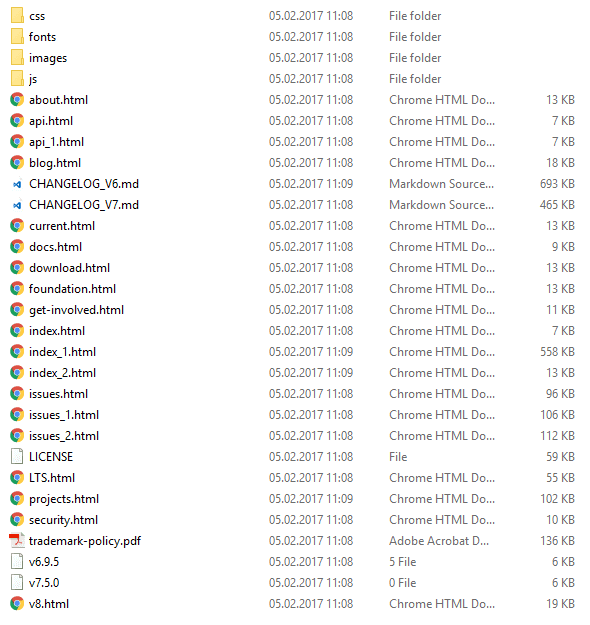
Фильтровать внешние URL
Как и ожидалось на любом веб-сайте, будут внешние URL-адреса, которые не принадлежат веб-сайту, который вы хотите скопировать. Чтобы эти страницы тоже не загружались, вы можете отфильтровать их, только если URL совпадает с тем, который вы используете:
const scrape = require('website-scraper');
const websiteUrl = 'https://nodejs.org';
let options = {
urls: [websiteUrl],
directory: './node-homepage',
// Enable recursive download
recursive: true,
// Follow only the links from the first page (index)
// then the links from other pages won't be followed
maxDepth: 1,
urlFilter: function(url){
// If url contains the domain of the website, then continue:
// https://nodejs.org with https://nodejs.org/en/example.html
if(url.indexOf(websiteUrl) === 0){
console.log(`URL ${url} matches ${websiteUrl}`);
return true;
}
return false;
},
};
scrape(options).then((result) => {
console.log("Webpages succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});Это должно уменьшить в нашем примере количество загруженных страниц:
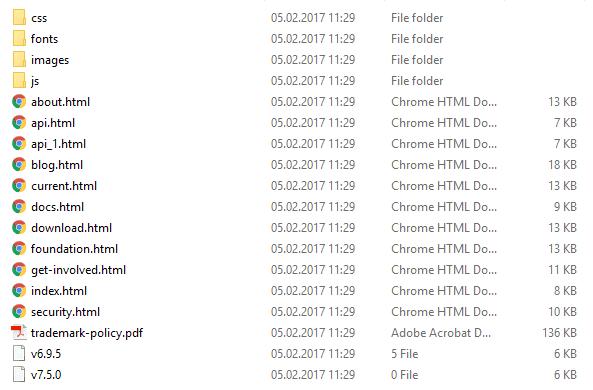
4. Скачать весь сайт
Заметка
Эта задача требует много времени, так что наберитесь терпения.
Если вы хотите загрузить весь веб-сайт, вы можете использовать модуль рекурсивной загрузки и увеличить максимально допустимую глубину до разумного числа (в этом примере это не так разумно с 50, но как угодно):
// Downloads all the crawlable files of example.com.
// The files are saved in the same structure as the structure of the website, by using the `bySiteStructure` filenameGenerator.
// Links to other websites are filtered out by the urlFilter
const scrape = require('website-scraper');
const websiteUrl = 'https://nodejs.org/';
scrape({
urls: [websiteUrl],
urlFilter: function (url) {
return url.indexOf(websiteUrl) === 0;
},
recursive: true,
maxDepth: 50,
prettifyUrls: true,
filenameGenerator: 'bySiteStructure',
directory: './node-website'
}).then((data) => {
console.log("Entire website succesfully downloaded");
}).catch((err) => {
console.log("An error ocurred", err);
});Окончательные рекомендации
Если CSS или JS-код веб-сайта минимизирован (и, вероятно, все они будут), мы рекомендуем вам использовать режим beautifier для языка (cssукрасить для css или же JS-украсить для Javascript), чтобы красиво печатать и делать код более читабельным (не так, как это делает оригинальный код, но приемлемо).