Содержание
Мы все время говорим о компьютерах, понимающих нас. Мы говорим, что Google «знал», что мы искали, или что Кортана «получила» то, что мы говорили, но «понимание» — очень сложная концепция. Особенно, когда речь идет о компьютерах.
Одна область компьютерной лингвистики, называемая обработка естественного языка (НЛП), работает над этой особенно сложной проблемой. Сейчас это увлекательное поле, и как только вы поймете, как оно работает, вы начнете видеть его влияние повсюду.
Быстрая заметка: В этой статье приведено несколько примеров того, как компьютер реагирует на речь, например, когда вы что-то просите у Сири. Преобразование слышимой речи в компьютерно-понятный формат называется распознаванием речи. НЛП не занимается этим (по крайней мере, в том качестве, о котором мы здесь говорим). НЛП вступает в игру только после того, как текст готов. Оба процесса необходимы для многих приложений, но это две совершенно разные проблемы.
Определение понимания
Прежде чем мы начнем понимать, как компьютеры работают с естественным языком, нам нужно определить несколько вещей.
Прежде всего, нам нужно определить естественный язык. Это легко: каждый язык, которым регулярно пользуются люди, попадает в эту категорию. Он не включает в себя такие вещи, как построенные языки (клингон, эсперанто) или языки программирования. Вы разговариваете со своими друзьями на естественном языке. Вы также, вероятно, используете это, чтобы поговорить с вашим цифровым личным помощником.
Итак, что мы имеем в виду, когда говорим «понимание»? Ну, это сложно. Что значит понимать предложение? Возможно, вы бы сказали, что это означает, что теперь у вас в мозгу намечено содержание сообщения. Понимание концепции может означать, что вы можете применить эту концепцию к другим мыслям.
Словарные определения туманны. Там нет интуитивного ответа. Философы спорили о таких вещах на протяжении веков.
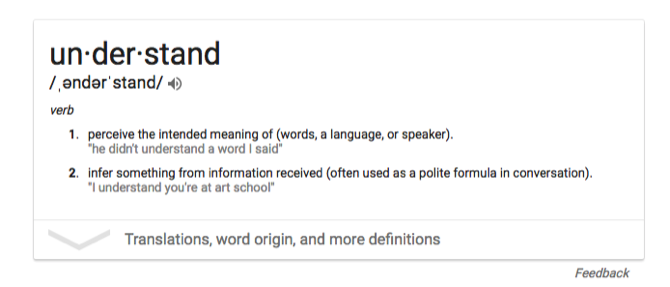
Для наших целей мы будем говорить, что понимание способность точно извлечь смысл из естественного языка. Чтобы компьютер мог понять, он должен точно обрабатывать входящий поток речи, преобразовывать этот поток в единицы значения и уметь отвечать на входные данные чем-то полезным.
Очевидно, это все очень расплывчато. Но это лучшее, что мы можем сделать с ограниченным пространством (и без степени нейрофилософии). Если компьютер может предложить человеческий или хотя бы полезный ответ на поток ввода естественного языка, мы можем сказать, что он понимает. Это определение, которое мы будем использовать в будущем.
Сложная проблема
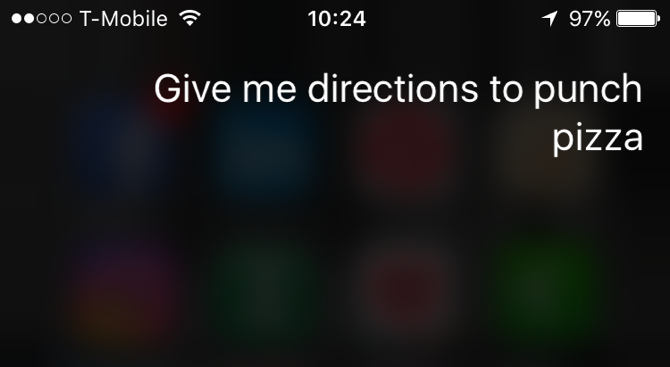
Естественный язык очень сложен для компьютера. Вы можете сказать: «Сири, дай мне дорогу к Punch Pizza», тогда как я могу сказать: «Siri, маршрут Punch Pizza, пожалуйста».
В вашем заявлении Siri может выбрать ключевую фразу «дай мне указания», а затем выполнить команду, связанную с поисковым термином «Punch Pizza». Однако в моем случае Siri нужно выбрать «route» в качестве ключевого слова и знать, что « Punch Pizza »- это то, куда я хочу пойти, а не« пожалуйста ». И это только упрощенный пример.
Подумайте об искусственном интеллекте, который читает электронные письма и решает, могут ли они быть мошенниками. Или тот, который отслеживает сообщения в социальных сетях, чтобы оценить интерес к конкретной компании. Однажды я работал над проектом, в котором мы должны были научить компьютер читать медицинские заметки (в которых есть всякие странные соглашения) и собирать из них информацию.
Это означает, что система должна была иметь дело с сокращениями, странным синтаксисом, случайными ошибками и множеством других отличий в примечаниях. Это очень сложная задача, которая может быть трудной даже для опытных людей, тем более машин.
Установка примера
В этом конкретном проекте я был частью команды, которая обучала компьютер распознавать конкретные слова и отношения между словами. Первым шагом процесса было показать компьютеру информацию, содержащуюся в каждой заметке, поэтому мы аннотировали заметки.
Было огромное количество разных категорий лиц и отношений. Возьмите предложение «Мисс Головная боль Грина лечилась ибупрофеном », например. Мисс грин был отмечен как ЧЕЛОВЕК, Головная боль был помечен как знак или симптом, ибупрофен был отмечен как МЕДИКАЦИЯ. Затем г-жа Грин была связана с головной болью с отношением PRESENTS. Наконец, ибупрофен был связан с головной болью с отношением TREATS.

Мы пометили тысячи заметок таким образом. Мы закодировали диагнозы, методы лечения, симптомы, основные причины, сопутствующие заболевания, дозы и все остальное, что вы, возможно, могли бы придумать, связанные с медициной. Другие команды аннотирования закодировали другую информацию, такую как синтаксис. В конце концов, у нас был корпус, полный медицинских записей, которые ИИ мог «прочитать».
Чтение так же трудно определить, как и понимание. Компьютер может легко увидеть, что ибупрофен лечит головную боль, но когда он узнает эту информацию, он превращается в бессмысленные (для нас) единицы и нули. Это, безусловно, может дать информацию, которая кажется похожей на человека и полезна, но означает ли это понимание
? Опять же, это в основном философский вопрос.
Настоящее обучение
В этот момент компьютер просмотрел записи и применил ряд алгоритмов машинного обучения.
, Программисты разработали различные процедуры для маркировки частей речи, анализа зависимостей и групп, а также для обозначения семантических ролей. По сути, ИИ учился «читать» заметки.
Исследователи могут в конечном итоге проверить его, предоставив ему медицинскую заметку и попросив пометить каждую сущность и отношение. Когда компьютер точно воспроизводил человеческие аннотации, можно было сказать, что он научился читать упомянутые медицинские заметки.
После этого нужно было собрать огромное количество статистических данных о том, что было прочитано: какие лекарства используются для лечения, какие расстройства, какие виды лечения наиболее эффективны, основные причины конкретных наборов симптомов и так далее. В конце процесса ИИ сможет отвечать на медицинские вопросы, основываясь на доказательствах из реальных медицинских записей. Он не должен полагаться на учебники, фармацевтические компании или интуицию.
Глубокое обучение
Давайте посмотрим на другой пример. Нейронная сеть Google DeepMind учится читать новостные статьи. Как и биомедицинский ИИ, описанный выше, исследователи хотели, чтобы он извлекал актуальную и полезную информацию из больших фрагментов текста.
Обучение ИИ по медицинской информации было достаточно трудным, поэтому вы можете представить, сколько аннотированных данных вам понадобится, чтобы ИИ мог читать статьи общих новостей. Наем достаточного количества аннотаторов и просмотр достаточного количества информации будет непомерно дорогим и трудоемким.
Поэтому команда DeepMind обратилась к другому источнику: новостным сайтам. В частности, CNN и Daily Mail.
Почему эти сайты? Потому что они предоставляют краткие резюме своих статей, которые не просто извлекают предложения из самой статьи. Это означает, что ИИ есть чему поучиться. Исследователи в основном говорили AI: «Вот статья и вот самая важная информация в ней». Затем они попросили ее извлечь информацию такого же типа из статьи без маркированных выделений.
Этот уровень сложности может быть обработан глубокой нейронной сетью, которая является особенно сложной системой машинного обучения. (Команда DeepMind делает некоторые удивительные вещи в этом проекте. Чтобы узнать подробности, посмотрите этот великолепный обзор из обзора технологий MIT.)
Что может сделать читающий AI?
Теперь у нас есть общее понимание того, как компьютеры учатся читать. Вы берете огромное количество текста, говорите компьютеру, что важно, и применяете некоторые алгоритмы машинного обучения. Но что мы можем сделать с ИИ, который извлекает информацию из текста?
Мы уже знаем, что вы можете извлечь конкретную полезную информацию из медицинских заметок и обобщить общие новостные статьи. Существует программа с открытым исходным кодом, которая называется P.A.N. который анализирует поэзию, вытаскивая темы и образы. Исследователи часто используют машинное обучение для анализа больших массивов данных в социальных сетях, которые компании используют для понимания настроений пользователей, просмотра высказываний людей и поиска полезных шаблонов для маркетинга.
Исследователи использовали машинное обучение, чтобы понять поведение электронной почты и последствия перегрузки электронной почты. Почтовые провайдеры могут использовать его для фильтрации спама из входящих сообщений и классификации некоторых сообщений как высокоприоритетных. Чтение ИИ имеет решающее значение в создании эффективных чат-ботов обслуживания клиентов
, Везде, где есть текст, есть исследователь, работающий над обработкой естественного языка.
И поскольку этот тип машинного обучения улучшается, возможности только увеличиваются. Компьютеры сейчас лучше, чем люди в шахматах, гоу и видеоиграх. Вскоре они могут стать лучше в чтении и обучении. Это первый шаг к сильному ИИ
? Нам придется подождать и посмотреть, но это может быть.
Какие виды использования вы видите для чтения текста и обучения AI? Как вы думаете, какие виды машинного обучения мы увидим в ближайшем будущем? Поделитесь своими мыслями в комментариях ниже!
Кредиты изображений: Васильев Александр / Shutterstock