Содержание
История вычислений полна провалов.
У Apple III была неприятная привычка готовить пищу в своей деформированной оболочке. Atari Jaguar, «инновационная» игровая приставка, которая имела некоторые ложные заявления о своей производительности, просто не могла захватить рынок. Флагманский процессор Intel Pentium, предназначенный для высокопроизводительных учетных приложений, испытывал трудности с десятичными числами.
Но другой тип флопа, который преобладает в мире вычислений, — это измерение FLOPS, которое давно принято считать разумным сравнением между различными машинами, архитектурами и системами.
FLOPS — это показатель операций с плавающей запятой в секунду. Проще говоря, это спидометр для компьютерной системы. И это росло в геометрической прогрессии в течение десятилетий.
Так что, если я скажу вам, что через несколько лет у вас будет система, сидящая на вашем столе, или на вашем телевизоре, или на вашем телефоне, которая сотрет пол современных суперкомпьютеров? Невероятный? Я сумасшедший? Посмотрите на историю, прежде чем судить.

Суперкомпьютер в Супермаркет
Недавний Intel i7 Haswell
процессор может выполнить около 177 миллиардов FLOPS (GFLOPS), что быстрее, чем самый быстрый суперкомпьютер в США в 1994 году, Sandia National Labs XP / s140 с 3680 вычислительными ядрами, работающими вместе.
PlayStation 4 может работать со скоростью около 1,8 триллиона FLOPS благодаря своей усовершенствованной микроархитектуре Cell и превзошла бы суперкомпьютер ASCI Red стоимостью 55 миллионов долларов, который возглавил мировую суперкомпьютерную лигу в 1998 году, почти за 15 лет до выпуска PS4.
IBM Watson AI System
имеет (текущий) пиковый режим работы 80 TFLOPS, и это далеко не близко к тому, чтобы включить его в список 500 лучших современных суперкомпьютеров, причем китайский Tianhe-2 возглавлял Top 500 в последние 3 раза подряд с пиковой производительностью 54 902 TFLOPS, или почти 55 Пета-Флопс.
Большой вопрос, где будет следующий настольный суперкомпьютер
собирается прийти? И что более важно, когда мы это получим?
Еще один кирпич в силовой стене
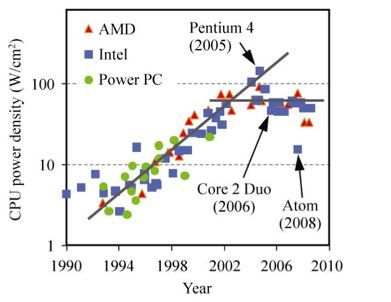
В недавней истории движущие силы между этими впечатляющими достижениями в скорости были в области материаловедения и архитектурного дизайна; Производственные процессы меньших нанометровых размеров означают, что чипы могут быть тоньше, быстрее и выделять меньше энергии в виде тепла, что делает их более дешевыми в эксплуатации.
Кроме того, с развитием многоядерных архитектур в конце 2000-х годов многие «процессоры» теперь умещаются в одном чипе. Эта технология в сочетании с растущей зрелостью распределенных вычислительных систем, в которых многие «компьютеры» могут работать как одна машина, означает, что Top 500 постоянно рос, почти в ногу со знаменитым законом Мура.
Тем не менее, законы физики начинают мешать всему этому росту, даже Intel беспокоится об этом, и многие по всему миру ищут следующую вещь.
… примерно через десять лет мы увидим крах закона Мура. Фактически, мы уже видим замедление закона Мура. Мощность компьютера просто не может поддерживать быстрый экспоненциальный рост с использованием стандартной кремниевой технологии. — Доктор Мичио Каку — 2012
Основная проблема с текущей схемой обработки заключается в том, что транзисторы либо включены (1), либо выключены (0). Каждый раз, когда затвор транзистора «переворачивается», он должен выбрасывать определенное количество энергии в материал, из которого сделаны затворы, чтобы этот «переворот» остался. По мере того как эти вентили становятся все меньше и меньше, соотношение между энергией для использования транзистора и энергией для «переворачивания» транзистора становится все больше и больше, что создает серьезные проблемы с нагревом и надежностью. Существующие системы приближаются, а в некоторых случаях даже превышают, к исходной плотности тепла ядерных реакторов, и материалы начинают выходить из строя их конструкторов. Это классически называется «Стена власти».
В последнее время некоторые начали по-другому думать о том, как выполнять полезные вычисления. В частности, две компании привлекли наше внимание с точки зрения современных форм квантовых и оптических вычислений. Канадские D-Wave Systems и британская Optalysys, у которых есть чрезвычайно разные подходы к очень различным наборам проблем.

Время менять музыку
В последнее время D-Wave получил большое количество прессы, со своим зловещим черным ящиком с супер-охлаждением и чрезвычайно острым внутренним шипом в киберпанке, содержащим загадочную голую фишку с трудными для воображения способностями.
По сути, система D2 использует совершенно другой подход к решению проблем, эффективно выбрасывая книгу причинно-следственных связей. Итак, на какие проблемы ориентируется этот гигант, поддерживаемый Google / NASA / Lockheed Martin?

Бродячий человек
Исторически сложилось так, что если вы хотите решить проблему NP-Hard или Intermediate, где существует чрезвычайно большое количество возможных решений с широким диапазоном возможностей, используя «значения», классический подход просто не работает. Возьмем, к примеру, проблему коммивояжера; учитывая N-городов, найдите кратчайший путь, чтобы посетить все города один раз. Важно отметить, что TSP является основным фактором во многих областях, таких как производство микрочипов, логистика и даже секвенирование ДНК,
Но все эти проблемы сводятся к очевидному простому процессу; Выберите точку, с которой нужно начать, создайте маршрут вокруг N «вещей», измерьте расстояние, и, если существует существующий маршрут, который короче его, откажитесь от предпринятого маршрута и переходите к следующему, пока не останется больше маршрутов для проверки.
Это звучит просто, и для небольших значений это так; для 3 городов есть 3 * 2 * 1 = 6 маршрутов для проверки, для 7 городов — 7 * 6 * 5 * 4 * 3 * 2 * 1 = 5040, что не так уж плохо для компьютера. Это факториальная последовательность, которая может быть выражена как «N!», Поэтому 5040 — это 7 !.
Однако к тому времени, когда вы пойдете немного дальше, чтобы посетить 10 городов, вам нужно протестировать более 3 миллионов маршрутов. К тому времени, как вы доберетесь до 100, количество маршрутов, которые вам нужно проверить, равно 9, а затем 157 цифры. Единственный способ взглянуть на функции такого рода — использовать логарифмический график, где ось Y начинается с 1 (10 ^ 0), 10 (10 ^ 1), 100 (10 ^ 2), 1000 (10 ^ 3). ) и так далее.
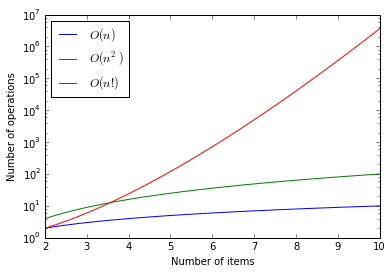
Числа просто становятся слишком большими, чтобы их можно было обрабатывать на любой машине, которая существует сегодня или может существовать с использованием классических вычислительных архитектур. Но то, что делает D-Wave, совсем другое.

Везувий появляется
Чип Везувия в D2 использует около 500 «кубитов» или квантовых битов для выполнения этих расчетов с использованием метода, называемого квантовым отжигом. Вместо того, чтобы измерять каждый маршрут за раз, кубиты Везувия переводятся в состояние суперпозиции (не включается и не выключается, работая вместе как своего рода потенциальное поле) и серии все более сложных алгебраических описаний решения (то есть серии гамильтонианов). описания решения, а не самого решения) применяются к полю суперпозиции.
По сути, система проверяет пригодность каждого потенциального решения одновременно, как мяч, «решающий», каким путем идти вниз по склону. Когда суперпозиция расслабляется в основное состояние, это основное состояние кубитов должно описывать оптимальное решение.
Многие задаются вопросом, какое преимущество дает система D-Wave по сравнению с обычным компьютером. В недавнем тестировании платформы против типичной задачи Traveling Saleman, которая заняла 30 минут для классического компьютера, потребовалось всего полсекунды на Везувий.
Однако, чтобы быть ясным, это никогда не будет системой, на которой вы играете в Doom. Некоторые комментаторы пытаются сравнить эту узкоспециализированную систему с процессором общего назначения. Вам лучше сравнить подводную лодку класса Огайо с F35 Lightning; любая метрика, которую вы выбираете для одной, настолько неуместна для другой, что бесполезна.
D-Wave работает на несколько порядков быстрее для своих специфических проблем по сравнению со стандартным процессором, и оценки FLOPS варьируются от относительно впечатляющих 420 GFLOPS до умопомрачительных 1,5 Peta-FLOPS (поместив его в топ-10 суперкомпьютера список 2013 года на момент последнего публичного прототипа). Во всяком случае, это несоответствие подчеркивает начало конца FLOPS как универсальное измерение применительно к конкретным проблемным областям.
Эта область вычислений нацелена на очень специфический (и очень интересный) набор проблем. К сожалению, одной из проблем в этой сфере является криптография
— особенно криптография с открытым ключом.
К счастью, реализация D-Wave, по-видимому, сфокусирована на алгоритмах оптимизации, и D-Wave приняла некоторые конструктивные решения (например, иерархическую пиринговую структуру на чипе), которые указывают, что вы не можете использовать Везувий для решения алгоритма Шора, который потенциально может разблокировать Интернет. так сильно, что это заставит Роберта Редфорда гордиться.
Лазерная математика
Вторая компания в нашем списке — Optalysys. Эта британская компания берет на себя вычисления и переворачивает их с ног на голову, используя аналоговую суперпозицию света для выполнения определенных классов вычислений с использованием самой природы света. Приведенное ниже видео демонстрирует некоторые общие сведения и основы системы Optalysys, представленные профессором Хайнцем Вольфом.
Это немного волнительно, но по сути, это коробка, которая, надеюсь, однажды сядет на ваш стол и обеспечит вычислительную поддержку для моделирования, CAD / CAM и медицинской визуализации (и, может быть, просто может быть, компьютерных игр). Как и в случае с Везувием, решение Optalysys не может выполнять основные вычислительные задачи, но это не то, для чего оно разработано.
Полезный способ думать об этом стиле оптической обработки — думать о нем как о физическом графическом процессоре (GPU). Современный GPU
Параллельно используют множество потоковых процессоров, выполняя одни и те же вычисления для разных данных, поступающих из разных областей памяти. Эта архитектура стала естественным результатом того, как генерируется компьютерная графика, но эта массивно параллельная архитектура использовалась для всего: от высокочастотной торговли до искусственных нейронных сетей.
Optalsys принимает аналогичные принципы и переводит их в физическую среду; разделение данных становится расщеплением луча, линейная алгебра становится квантовой интерференцией, функции стиля MapReduce становятся системами оптической фильтрации. И все эти функции работают в постоянном, практически мгновенном, времени.
Первоначальное устройство-прототип использует элементарную сетку 20 Гц 500 × 500 для выполнения быстрых преобразований Фурье (в основном, «какие частоты появляются в этом входном потоке?») И обеспечивает неимоверный эквивалент 40 GFLOPS. Разработчики нацеливаются на систему 340 GFLOPS к следующему году, что, учитывая предполагаемое энергопотребление, будет впечатляющим результатом.
Так где мой черный ящик?
История вычислений
показывает нам, что то, что изначально является резервом исследовательских лабораторий и государственных учреждений, быстро пробивается в потребительское оборудование. К сожалению, история вычислений еще не сталкивалась с ограничениями законов физики.
Лично я не думаю, что D-Wave и Optalysys будут точными технологиями, которые мы будем иметь на наших рабочих столах через 5-10 лет. Учтите, что первые узнаваемые «умные часы» были представлены в 2000 году и с треском провалились; но суть технологии продолжается и сегодня. Аналогичным образом, эти исследования ускорителей квантовых и оптических вычислений, скорее всего, окажутся сносками в «следующей большой вещи».
Материаловедение приближается к биологическим компьютерам, используя ДНК-подобные структуры для выполнения математических операций. Нанотехнология и «Программируемый вопрос» приближаются к точке, в которой они не обрабатывают «данные», а сам материал будет содержать, представлять и обрабатывать информацию.
В общем, это дивный новый мир для вычислительного ученого. Как вы думаете, куда это все идет? Давайте поговорим об этом в комментариях!
Фото предоставлены: KL Intel Pentium A80501, Константин Ланцет, Asci red — tflop4m, правительство США — Национальная лаборатория Сандиа, DWave D2 от Ванкуверского Солнца, DWave 128chip от D-Wave Systems, Inc., Задача коммивояжера Рэндалла Манро (XKCD)