Содержание
Давайте представим, что вам нужно оцифровать страницу книги или печатного документа, вы будете использовать сканер для создания изображения реальной страницы. Однако, несмотря на то, что у вас есть права на редактирование содержимого отсканированной книги, вы не можете редактировать его на своем компьютере, потому что это изображение, и вы не можете просто отредактировать изображение, как если бы это был цифровой документ. Да, пользователь может использовать программы, которые создают PDF с возможностью выбора текста, а затем они могут делать то, что хотят, однако, как разработчик, вы можете предложить своему пользователю возможность извлекать текст из изображений с помощью технологии оптического распознавания символов. Чтобы достичь цели преобразования изображений в текст, мы собираемся использовать Tesseract, написанный на C ++, установить его в системе, а затем использовать командную строку с оболочкой PHP.
В этой статье вы узнаете, как извлечь текст из изображения в проекте Symfony с помощью Tesseract.
1. Установите Tesseract в вашей системе
Чтобы использовать API оптического распознавания символов, как упоминалось в статье, мы собираемся использовать Tesseract. Тессеракт является механизмом оптического распознавания символов (OCR) с открытым исходным кодом, доступным по лицензии Apache 2.0. Его можно использовать напрямую с помощью API для извлечения печатного, рукописного или печатного текста из изображений. Он поддерживает широкий спектр языков (которые должны быть установлены). Tesseract поддерживает различные форматы вывода: обычный текст, hocr (html) и pdf.
Процесс установки Tesseract в вашей системе зависит от используемой вами операционной системы:
Windows
Установка Tesseract в Windows довольно проста, мы рекомендуем вам использовать неофициальный установщик, упомянутый в вики здесь (tesseract-ocr-setup-.exe). Ты можешь получить список всех доступных настроек на официальном сайте tesseract здесь (всегда загружайте самую последнюю версию).
Процесс установки очень прост, просто следуйте инструкциям мастера. Однако мы рекомендуем вам установить в настройках непосредственно все языки, которые вам нужны для tesseract (только те, которые вам нужны, в противном случае процесс загрузки займет много времени) и зарегистрировать tesseract в PATH:
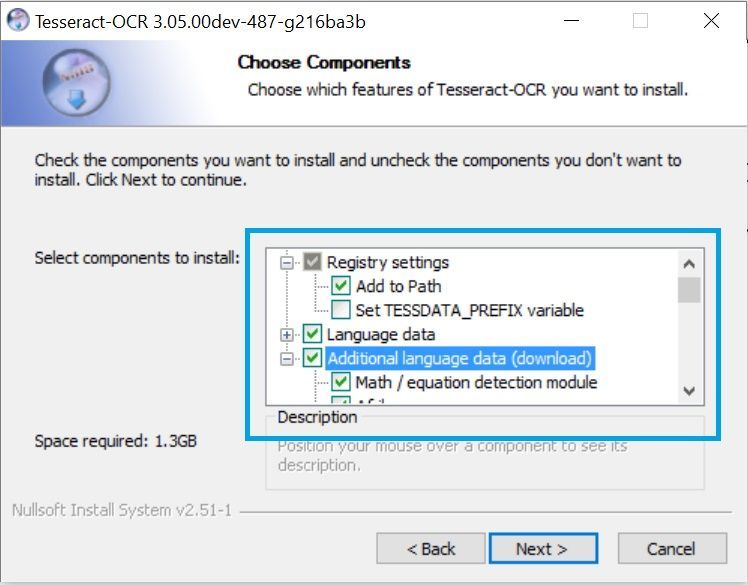
Подождите, пока установка закончится, и вы готовы к работе. Вы можете проверить, правильно ли он был установлен, запустив новое окно командной строки. tesseract -v (это должно вывести установленную версию).
Ubuntu
Установите Tesseract с помощью следующей команды:
sudo apt-get install tesseract-ocrЗатем установите языки, которые необходимо распознать (например, -deu, -fra, -eng, -spa требуемый английский):
sudo apt-get install tesseract-ocr-engТогда tesseract должен быть доступен на любом терминале и, следовательно, доступен для наших сценариев PHP позже.
MacOS
Если вы используете Mac OS X, вы можете установить tesseract, используя либо MacPorts или же Homebrew:
MacPorts
Чтобы установить Tesseract, запустите эту команду:
sudo port install tesseractЧтобы установить любые языковые данные, выполните:
sudo port install tesseract-Полный список доступных langcodes можно найти на Страница тессеракт MacPorts.
Homebrew
Чтобы установить Tesseract, запустите эту команду:
brew install tesseractЕсли вам нужна дополнительная информация или вашей операционной системы нет в списке, обратитесь к Установка вики репозитория Tesseract в Github здесь.
2. Установите PHP-оболочку Tesseract
Для работы с Tesseract с помощью PHP мы будем использовать самый известный Wrapper of Tesseract, написанный @thiagoalessio. Тессеракт OCR для PHP является полезной и очень простой в использовании оболочкой инструкций командной строки для Tesseract OCR внутри PHP.
Предпочтительный способ установки — через композитор, вы можете выполнить следующую команду прямо в терминале:
composer require thiagoalessio/tesseract_ocr 1.0.0-RCИли, если хотите, отредактируйте composer.json файл и добавьте следующую зависимость и выполните затем composer install:
{
"require": {
"thiagoalessio/tesseract_ocr": "1.0.0-RC",
}
}
После установки вы сможете использовать Wrapper в ваших контроллерах Symfony.
Замечания: вам нужно установить указанную версию, как в документации библиотеки, метод распознавания текста на изображении с использованием Tesseract $tesseract->run(), В старых версиях вам нужно использовать $tesseract->recognize() вместо.
3. Реализация в контроллере
Использование библиотеки довольно просто и легко понять:
run();
// Show recognized text
echo $result;В следующем примере показано, как распознать текст следующего изображения:

Обратите внимание, что файл будет находиться в /your-project/web/text.jpeg:
get('kernel')->getRootDir().'/../web/';
// The filename of the image is text.jpeg and is located inside the web folder
$filepath = $webPath.'text.jpeg';
// Is useful to verify if the file exists, because the tesseract wrapper
// will throw an error but without description
if(!file_exists($filepath)){
return new Response("Warning: the providen file [".$filepath."] doesn't exists.");
}
// Create a new instance of tesseract and provide as first parameter
// the local path of the image
$tesseractInstance = new TesseractOCR($filepath);
// Execute tesseract to recognize text
$result = $tesseractInstance->run();
// Return the recognized text as response (expected: The quick brown fox jumps over the lazy dog.)
return new Response($result);
}
}
Перейдите к маршруту, который соответствует действию индекса этого контроллера, и вы увидите, как выводится распознанный текст изображения.
4. Поддержка языков
Как вы знаете, в мире есть другие языки, в которых используются специальные символы, поэтому Tesseract предлагает различные языковые пакеты. Например, если вы попытаетесь распознать следующее изображение без немецкого пакета:

В результате вы получите «грифон». Это совсем не так, это происходит потому, что эти персонажи немецкого языка. Чтобы решить эту проблему, вам нужно добавить немецкий пакет (обозначается как deu):
lang("deu");
// Execute tesseract to recognize text
$result = $tesseractInstance->run();
echo $result;Теперь, как результат, вы должны получить «grüßen», как и ожидалось. Вы можете настроить одновременную работу нескольких языков, указав несколько аргументов:
$tesseractInstance->lang("deu", "spa", "por");Замечания: чтобы использовать разные языки, вам также понадобятся соответствующие пакеты.
5. Пользовательские параметры
Если вы уже прочитали некоторое содержание документация по использованию Tesseract с командной строкой, Вы знаете, что есть много свойств, которые вы можете изменить. Оболочка PHP tesseract предоставляет несколько методов для наиболее часто используемых опций:
Изменить путь к исполняемому файлу
По разным причинам у вас может не быть доступного tesseract непосредственно в переменной окружения PATH, поэтому выполнение команды с помощью оболочки php «tesseract imagename.jpeg outputbase«не будет работать. Вы можете указать расположение исполняемого файла tesseract с помощью исполняемого метода:
$tsaInstance = new TesseractOCR("image.jpeg");
// For example in Windows, you need to wrapp the path in double quotes to make it work.
$executablePath = '"C:/Program Files (x86)/Tesseract-OCR/tesseract.exe"';
$tsaInstance->executable($executablePath);
$recognized = $tsaInstance->run();Сегментация страницы
Вы можете установить режим сегментации страницы с помощью ->psm($mode) инструкция, которая инструктирует тессеракт, как интерпретировать данное изображение:
$tsaInstance = new TesseractOCR("image.jpeg");
$tsaInstance->psm(1);
$recognized = $tsaInstance->run();Возможные значения для сегментации страницы:
| Значение | Описание |
| Только ориентация и обнаружение сценариев (OSD). | |
| 1 | Автоматическая сегментация страницы с помощью экранного меню. |
| 2 | Автоматическая сегментация страницы, но без OSD или OCR. |
| 3 | Полностью автоматическая сегментация страниц, но без OSD. (Это значение используется по умолчанию, если ни один не предоставлен) |
| 4 | Предположим, что один столбец текста переменного размера. |
| 5 | Предположим, что один однородный блок текста вертикально выровнен. |
| 6 | Предположим, что один единый блок текста. |
| 7 | Рассматривайте изображение как одну текстовую строку. |
| 8 | Рассматривайте изображение как одно слово. |
| 9 | Рассматривайте изображение как одно слово в кругу. |
| 10 | Относитесь к изображению как к одному персонажу. |
Установите языки для распознавания
Вы можете определить один или несколько языков, которые будут использоваться во время распознавания, используя ->lang($lang1, $lang2) метод. Вы можете получить список все поддерживаемые языки по tesseract в документации здесь:
$tsaInstance = new TesseractOCR("image.jpeg");
// To provide full chinese recognition
$tsaInstance->lang('chi_sim', 'chi_tra');
$recognized = $tsaInstance->run();Используйте слова из списка
Вы можете предоставить список. этот список должен быть простым текстовым файлом, содержащим список слов, которые вы хотите, чтобы tesseract считал обычными словарными словами, например (mywords.txt):
jargon
artyom.js
recognitionИ добавьте это с оберткой:
$tsaInstance = new TesseractOCR("image.jpeg");
// Custom words
$tsaInstance->userWords('mywords.txt');
$recognized = $tsaInstance->run();Этот список действительно полезен при работе с контентом, который содержит техническую терминологию.
Белый список персонажей
Вы можете даже ограничить символы, которые распознает tesseract, например, с помощью следующего изображения:
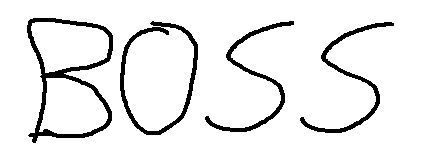
Тессеракт узнает "BOSS", Это здорово, потому что на картинке кажется, что кто-то написал БОСС, но пользователь (вероятно, ребенок или кто-то с плохой каллиграфией) написал число «8055» ? Вот где белый список пригодится, в этом случае мы можем ограничить символы для распознавания только чисел, используя диапазон от 0 до 9:
$tsaInstance = new TesseractOCR("image.jpeg");
// Recognize all in numbers
$tsaInstance->whitelist(range(0,9));
$recognized = $tsaInstance->run();Предоставление в результате ожидаемого числа «8055».
Установить значение конфигурации
Tesseract предлагает более 600 настраиваемых свойств (вы можете перечислить их, используя в консоли tesseract --print-parameters) что вы можете изменить с помощью ->config($propertyName, $value):
$tsaInstance = new TesseractOCR("image.jpeg");
// Size of window for spline segmentation
$tsaInstance->config("textord_spline_medianwin", 6 );
// For smooth factor
$tsaInstance->config("textord_skewsmooth_offset", 3);
$recognized = $tsaInstance->run();Если вам нужна дополнительная информация о поддерживаемых методах этой оболочки, пожалуйста, посетите официальный репозиторий здесь.


