Если вы запускаете сайт
вы, вероятно, слышали о файле robots.txt (или «стандарте исключения роботов»). Есть ли у вас или нет, пришло время узнать об этом, потому что этот простой текстовый файл является важной частью вашего сайта. Это может показаться незначительным, но вы можете быть удивлены, насколько это важно.
Давайте посмотрим, что такое файл robots.txt, что он делает и как правильно настроить его для вашего сайта.
Что такое файл robots.txt?
Чтобы понять, как работает файл robots.txt, вам нужно немного узнать о поисковых системах
, Короче говоря, они рассылают «сканеры», которые представляют собой программы, которые ищут информацию в Интернете. Затем они хранят часть этой информации, чтобы потом можно было направлять людей к ней.
Эти сканеры, также известные как «боты» или «пауки», находят страницы на миллиардах веб-сайтов. Поисковые системы дают им указания о том, куда идти, но отдельные сайты также могут общаться с ботами и сообщать им, на каких страницах они должны смотреть.
Большую часть времени они фактически делают обратное и сообщают им, на какие страницы они не должны смотреть. Такие вещи, как административные страницы, серверные порталы, страницы категорий и тегов и другие вещи, которые владельцы сайтов не хотят отображать в поисковых системах. Эти страницы по-прежнему видны пользователям, и они доступны любому, у кого есть разрешение (которым часто являются все).
Но, сказав этим паукам не индексировать некоторые страницы, файл robots.txt оказывает всем услугу. Если бы вы искали «MakeUseOf» в поисковой системе, вы бы хотели, чтобы наши административные страницы показывались высоко в рейтинге? Нет. Это никому не поможет, поэтому мы просим поисковые системы не показывать их. Его также можно использовать, чтобы не дать поисковым системам проверять страницы, которые могут не помочь им классифицировать ваш сайт в результатах поиска.
Короче говоря, robots.txt сообщает сканерам, что делать.
Могут ли сканеры игнорировать robots.txt?
Искатели когда-нибудь игнорируют файлы robots.txt? Да. Фактически, многие сканеры игнорируют это. Однако, как правило, эти сканеры не из авторитетных поисковых систем. Они от спамеров, сборщиков электронной почты и других типов автоматических ботов, которые бродят по Интернету. Важно помнить об этом — использование стандарта исключения роботов для предупреждения ботов не является эффективной мерой безопасности. На самом деле, некоторые боты могут начинать со страниц, на которые вы говорите им не заходить.
Однако поисковые системы будут делать то, что говорит ваш файл robots.txt, если он правильно отформатирован.
Как написать файл robots.txt
Есть несколько разных частей, которые входят в стандартный файл исключения роботов. Я разбью их здесь по отдельности.
Объявление агента пользователя
Прежде чем сообщить боту, на какие страницы он не должен смотреть, вы должны указать, с каким ботом вы общаетесь. В большинстве случаев вы будете использовать простое объявление, которое означает «все боты». Это выглядит так:
User-agent: *Звездочка обозначает «все боты». Однако вы можете указать страницы для определенных ботов. Для этого вам нужно знать имя бота, для которого вы выкладываете инструкции. Это может выглядеть так:
User-agent: Googlebot
[list of pages not to crawl]
User-agent: Googlebot-Image/1.0
[list of pages not to crawl]
User-agent: Bingbot
[list of pages not to crawl]И так далее. Если вы обнаружите бота, который вообще не хочет сканировать свой сайт, вы можете указать и это.
Чтобы найти имена пользовательских агентов, проверьте useragentstring.com.
Запрещение страниц
Это основная часть вашего файла исключения роботов. Простым объявлением вы указываете боту или группе ботов не сканировать определенные страницы. Синтаксис прост. Вот как вы можете запретить доступ ко всему, что находится в каталоге «admin» вашего сайта:
Disallow: /admin/Эта строка не позволит ботам сканировать yoursite.com/admin, yoursite.com/admin/login, yoursite.com/admin/files/secret.html и все остальное, что попадает в каталог администратора.
Чтобы запретить одну страницу, просто укажите ее в строке запрета:
Disallow: /public/exception.htmlТеперь страница «исключения» не будет перетянута, но все остальное в папке «public» будет.
Чтобы включить несколько каталогов или страниц, просто перечислите их в следующих строках:
Disallow: /private/
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /temp/Эти четыре строки будут применяться к любому пользовательскому агенту, который вы указали в верхней части раздела.
Если вы хотите, чтобы боты не смотрели какую-либо страницу на вашем сайте, используйте это:
Disallow: /Установка различных стандартов для ботов
Как мы видели выше, вы можете указать определенные страницы для разных ботов. Комбинируя предыдущие два элемента, вот как это выглядит:
User-agent: googlebot
Disallow: /admin/
Disallow: /private/
User-agent: bingbot
Disallow: /admin/
Disallow: /private/
Disallow: /secret/Разделы «admin» и «private» будут невидимы в Google и Bing, но Google увидит «секретный» каталог, а Bing — нет.
Вы можете указать общие правила для всех ботов, используя пользовательский агент звездочки, а затем дать конкретные инструкции для ботов в последующих разделах.
Собираем все вместе
Обладая знаниями выше, вы можете написать полный файл robots.txt. Просто запустите ваш любимый текстовый редактор (мы поклонники Sublime
где-то здесь) и начните сообщать ботам, что они не приветствуются в определенных частях вашего сайта.
Если вы хотите увидеть пример файла robots.txt, просто зайдите на любой сайт и добавьте «/robots.txt» в конец. Вот часть файла Giant Bicycles robots.txt:
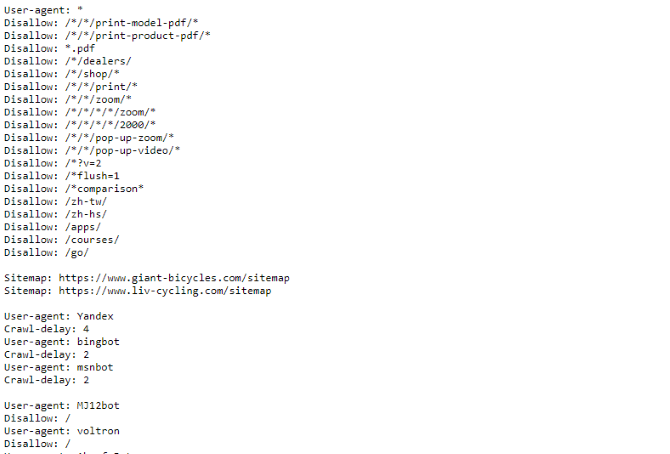
Как вы можете видеть, есть довольно много страниц, которые они не хотят показывать в поисковых системах. Они также включили несколько вещей, о которых мы еще не говорили. Давайте посмотрим, что еще вы можете сделать в своем файле исключения роботов.
Расположение вашего сайта
Если ваш файл robots.txt сообщает ботам, куда не следует переходить, ваша карта сайта делает наоборот
и помогает им найти то, что они ищут. И хотя поисковые системы, вероятно, уже знают, где находится ваша карта сайта, не повредит сообщить им об этом снова.
Объявление местоположения карты сайта простое:
Sitemap: [URL of sitemap]Это оно.
В нашем собственном файле robots.txt это выглядит так:
Sitemap: //www.makeuseof.com/sitemap_index.xmlЭто все, что нужно сделать.
Установка задержки сканирования
Директива задержки сканирования сообщает определенным поисковым системам, как часто они могут проиндексировать страницу на вашем сайте. Он измеряется в секундах, хотя некоторые поисковые системы интерпретируют его немного по-другому. Некоторые видят, что задержка сканирования 5 означает, что они должны ждать пять секунд после каждого сканирования, чтобы начать следующий. Другие интерпретируют это как инструкцию сканировать только одну страницу каждые пять секунд.
Почему вы бы сказали сканеру не сканировать как можно больше? Чтобы сохранить пропускную способность
, Если ваш сервер не справляется с трафиком, вы можете установить задержку сканирования. В общем, большинству людей не нужно беспокоиться об этом. Большие сайты с большим трафиком, однако, могут захотеть немного поэкспериментировать.
Вот как вы устанавливаете задержку сканирования в восемь секунд:
Crawl-delay: 8Это оно. Не все поисковые системы будут подчиняться вашей директиве. Но это не больно спрашивать. Как и при запрете страниц, вы можете установить различные задержки сканирования для определенных поисковых систем.
Загрузка файла robots.txt
Как только у вас есть все инструкции в вашем файле, вы можете загрузить его на свой сайт. Убедитесь, что это простой текстовый файл с именем robots.txt. Затем загрузите его на свой сайт, чтобы найти его на yoursite.com/robots.txt.
Если вы используете систему управления контентом
Как и в случае с WordPress, вам, вероятно, понадобится особый способ сделать это. Поскольку это отличается в каждой системе управления контентом, вам необходимо обратиться к документации для вашей системы.
Некоторые системы также могут иметь онлайн-интерфейсы для загрузки вашего файла. Для этого просто скопируйте и вставьте файл, созданный на предыдущих шагах.
Не забудьте обновить файл
Последний совет, который я дам, — время от времени просматривать ваш файл исключения роботов. Ваш сайт меняется, и вам может потребоваться внести некоторые изменения. Если вы заметили странное изменение в трафике вашей поисковой системы, рекомендуется также проверить файл. Также возможно, что стандартное обозначение может измениться в будущем. Как и все остальное на вашем сайте, стоит время от времени проверять его.
С каких страниц вы исключаете сканеры на своем сайте? Вы заметили какую-либо разницу в поисковом трафике? Поделитесь своими советами и комментариями ниже!