Вы верите в то, что если что-то опубликовано в Интернете, оно публикуется навсегда? Что ж, сегодня мы собираемся развеять этот миф.
Правда в том, что во многих случаях вполне возможно искоренить информацию из Интернета. Конечно, есть запись веб-страниц, которые были удалены, если вы ищете Wayback Machine, верно? Да, абсолютно. На Wayback Machine есть записи о веб-страницах, появившихся много лет назад — страницы, которые вы не найдете с помощью поиска Google, потому что веб-страница больше не существует. Кто-то удалил его, или сайт был закрыт.
Так что, обойти это невозможно, верно? Информация навсегда будет выгравирована на камне Интернета, что там увидят поколения? Ну, не совсем так.
Правда в том, что, хотя может быть трудно или невозможно уничтожить основные новостные материалы, которые распространялись с одного новостного сайта или блога на другой, как вирус, на самом деле довольно легко полностью удалить веб-страницу или несколько веб-страниц из всех записей. существования — удалить эту страницу как для поисковых систем, так и для Wayback Machine
, Конечно, есть одна загвоздка, но мы вернемся к этому.
3 способа удалить страницы блога из сети
Первый метод — тот, который используют большинство владельцев веб-сайтов, потому что они не знают ничего лучше — просто удаляют веб-страницы. Это может произойти из-за того, что вы поняли, что на вашем сайте есть дублированный контент, или из-за того, что у вас есть страница, которую вы не хотите показывать в результатах поиска.
Просто удалите страницу
Проблема с полным удалением страниц с вашего веб-сайта заключается в том, что, поскольку вы уже создали страницу в сети, скорее всего, будут ссылки с вашего собственного сайта, а также внешние ссылки с других сайтов на эту конкретную страницу. Когда вы удаляете его, Google немедленно распознает вашу страницу как отсутствующую.
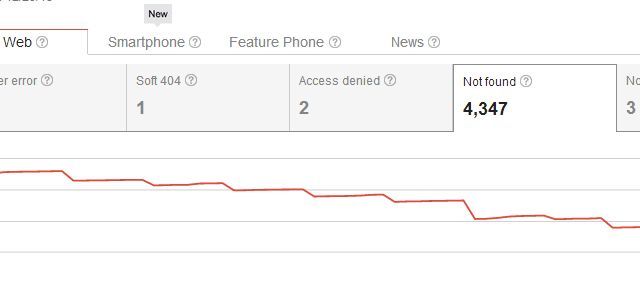
Таким образом, удаляя свою страницу, вы не только создали проблему с ошибками сканирования «Не найдено», но и создали проблему для всех, кто когда-либо ссылался на страницу. Обычно пользователи, которые попадают на ваш сайт по одной из этих внешних ссылок, увидят вашу страницу 404, что не является большой проблемой, если вы используете что-то вроде пользовательского кода 404 Google, чтобы предоставить пользователям полезные предложения или альтернативы. Но вы думаете, что могут быть более изящные способы удаления страниц из результатов поиска, не используя все эти 404 для существующих входящих ссылок, верно?
Ну, есть.
Удалить страницу из результатов поиска Google
Прежде всего, вы должны понимать, что если веб-страница, которую вы хотите удалить из результатов поиска Google, не является страницей с вашего собственного сайта, то вам не повезло, если на то нет законных причин или сайт опубликовал вашу личную информацию. информация онлайн без вашего разрешения. В таком случае воспользуйтесь средством устранения неполадок при удалении Google, чтобы отправить запрос на удаление страницы из результатов поиска. Если у вас есть действительный случай, вы можете добиться успеха, удалив страницу — конечно, вы можете добиться еще большего успеха, просто связавшись с владельцем сайта.
как я описал, как это сделать еще в 2009 году.
Теперь, если страница, которую вы хотите удалить из результатов поиска, находится на вашем собственном сайте, вам повезло. Все, что вам нужно сделать, это создать файл robots.txt и убедиться, что вы запретили указывать определенную страницу, которую вы не хотите видеть в результатах поиска, или весь каталог с содержимым, которое вы не хотите индексировать. Вот как выглядит блокировка одной страницы.
User-agent: * Disallow: /my-deleted-article-that-i-want-removed.html
Вы можете заблокировать ботов от сканирования целых каталогов вашего сайта следующим образом.
User-agent: * Disallow: /content-about-personal-stuff/
У Google есть отличная страница поддержки, которая может помочь вам создать файл robots.txt, если вы никогда его не создавали. Это работает очень хорошо, как я недавно объяснил в статье о структурировании сделок синдикации
чтобы они не причинили вам вреда (попросив партнеров по синдикации запретить индексацию своих страниц там, где вы синдицированы). Как только мой партнер по синдикации согласился сделать это, страницы с дублированным контентом из моего блога полностью исчезли из поисковых списков.
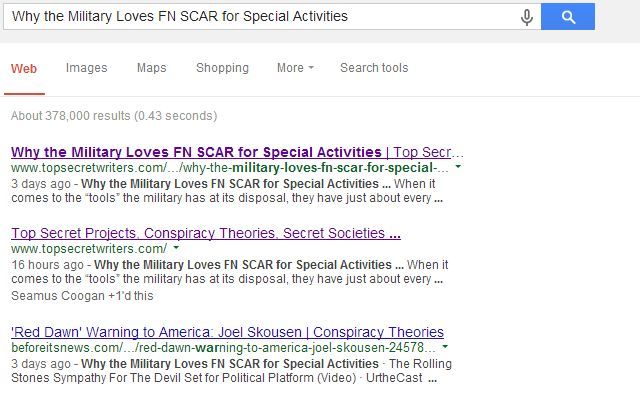
Только основной веб-сайт занимает третье место для страницы, где они перечисляют наш заголовок, но мой блог теперь указан как на первом, так и на втором месте; что-то, что было бы почти невозможно, если бы сайт с более высоким авторитетом оставил проиндексированную дублированную страницу.
Многие люди не понимают, что этого также можно достичь с помощью Интернет-архива (Wayback Machine). Вот строки, которые нужно добавить в файл robots.txt, чтобы это произошло.
User-agent: ia_archiver Disallow: /sample-category/
В этом примере я говорю интернет-архиву, что нужно удалить что-либо из подкаталога категории-образца на моем сайте с Wayback Machine. Интернет-архив объясняет, как это сделать, на странице справки об исключении. Здесь также объясняется, что «Интернет-архив не заинтересован в предоставлении доступа к веб-сайтам или другим интернет-документам, авторы которых не хотят, чтобы их материалы находились в коллекции».
Это противоречит общепринятому мнению, что все, что публикуется в Интернете, попадает в архив на всю вечность. Нет, веб-мастера, владеющие контентом, могут специально удалить контент из архива, используя подход robots.txt.
Удалить отдельную страницу с метатегами
Если у вас есть только несколько отдельных страниц, которые вы хотите удалить из результатов поиска Google, вам вообще не нужно использовать подход robots.txt, вы можете просто добавить правильный метатег «роботы» на отдельные страницы, и сказать роботам не индексировать и не переходить по ссылкам на всей странице.
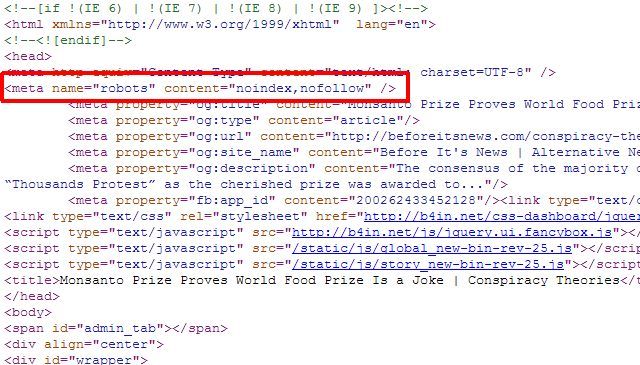
Вы можете использовать мету «роботы», описанную выше, чтобы запретить роботам индексировать страницу, или вы можете указать роботу Google не индексировать страницу, чтобы страница удалялась только из результатов поиска Google, а другие поисковые роботы могли по-прежнему получать доступ к содержимому страницы.
От вас зависит, как вы захотите управлять тем, что роботы делают со страницей, и будет ли страница указана в списке. Для нескольких отдельных страниц это может быть лучшим подходом. Чтобы удалить весь каталог содержимого, используйте метод robots.txt.
Идея «удаления» контента
Такого рода идея «удаления контента из Интернета» перевернулась с ног на голову. Технически, если вы удалите все свои собственные ссылки на страницу на своем сайте и удалите их из Поиска в Google и Интернет-архива с использованием метода robots.txt, эта страница для всех намерений и целей будет «удалена» из Интернета. Круто то, что при наличии существующих ссылок на страницу эти ссылки будут работать, и вы не вызовете 404 ошибки для этих посетителей.
Это более «щадящий» подход к удалению контента из Интернета без полного искажения существующей ссылки на вашем сайте в Интернете. В конце концов, как вы поступите с управлением контентом, собираемым поисковыми системами, и Интернет-архив зависит от вас, но всегда помните, что, несмотря на то, что люди говорят о продолжительности жизни вещей, публикуемых в Интернете, это действительно полностью под вашим контролем. ,




