Содержание
Предположим, вам нужно оцифровать страницу книги или печатного документа, вы будете использовать сканер для создания изображения реальной страницы. Однако, хотя у вас есть права на редактирование содержимого отсканированного документа, вы не можете редактировать его на своем компьютере, потому что это изображение, и вы не можете просто отредактировать изображение, как если бы это был цифровой документ. Да, пользователь может использовать программы, которые создают PDF с возможностью выбора текста, а затем они могут делать то, что хотят, однако, как разработчик, вы можете предложить своему пользователю возможность извлекать текст из изображений с помощью технологии оптического распознавания символов. Чтобы достичь цели преобразования изображений в текст, мы собираемся использовать Tesseract, написанный на C ++, установить его в системе, а затем использовать командную строку с оболочкой Node.js.
В этой статье вы узнаете, как извлечь текст из изображения с помощью Tesseract с использованием Javascript в Node.js.
1. Установите Tesseract в вашей системе
Чтобы использовать API оптического распознавания символов, как уже упоминалось в статье, мы будем использовать Tesseract. Тессеракт является механизмом оптического распознавания символов (OCR) с открытым исходным кодом, доступным по лицензии Apache 2.0. Его можно использовать напрямую с помощью API для извлечения печатного, рукописного или печатного текста из изображений. Он поддерживает широкий спектр языков (которые должны быть установлены). Tesseract поддерживает различные форматы вывода: обычный текст, hocr (html) и pdf.
Процесс установки Tesseract в вашей системе зависит от используемой вами операционной системы:
Windows
Установка Tesseract в Windows довольно проста, мы рекомендуем вам использовать неофициальный установщик, упомянутый в вики здесь (tesseract-ocr-setup-.exe). Ты можешь получить список всех доступных настроек на официальном сайте tesseract здесь (всегда загружайте самую последнюю версию).
Процесс установки очень прост, просто следуйте инструкциям мастера. Однако мы рекомендуем вам установить в настройках непосредственно все языки, которые вам нужны для tesseract (только те, которые вам нужны, в противном случае процесс загрузки займет много времени) и зарегистрировать tesseract в PATH:
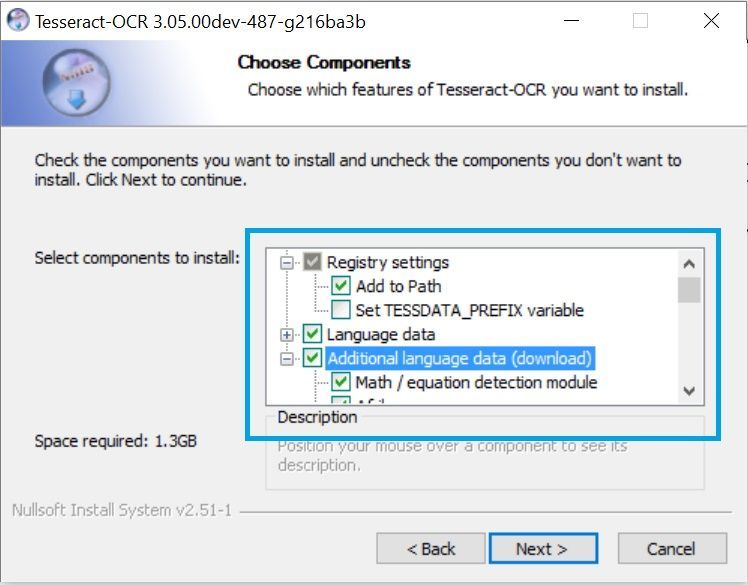
Подождите, пока установка закончится, и вы готовы к работе. Вы можете проверить, правильно ли он был установлен, запустив новое окно командной строки. tesseract -v (это должно вывести установленную версию).
Ubuntu
Установите Tesseract с помощью следующей команды:
sudo apt-get install tesseract-ocrЗатем установите языки, которые необходимо распознать (например, -deu, -fra, -eng, -spa требуемый английский):
sudo apt-get install tesseract-ocr-engТогда tesseract должен быть доступен на любом терминале и, следовательно, доступен для наших сценариев PHP позже.
MacOS
Если вы используете Mac OS X, вы можете установить tesseract, используя либо MacPorts или же Homebrew:
MacPorts
Чтобы установить Tesseract, запустите эту команду:
sudo port install tesseractЧтобы установить любые языковые данные, выполните:
sudo port install tesseract-Полный список доступных langcodes можно найти на Страница тессеракт MacPorts.
Homebrew
Чтобы установить Tesseract, запустите эту команду:
brew install tesseractЕсли вам нужна дополнительная информация или вашей операционной системы нет в списке, обратитесь к Установка вики репозитория Tesseract в Github здесь.
2. Установите оболочку Tesseract Node.js
Для работы с Tesseract с Node.js мы будем использовать самый известный Wrapper of Tesseract, написанный @desmondmorris. Модуль node-tesseract является очень простой оболочкой для пакета OCR Tesseract для node.js, для него требуется Tesseract 3.01 или выше.
Чтобы установить node-tesseract Модуль в вашем проекте Node.js выполняет следующую команду:
npm install node-tesseractТогда вы сможете потребовать модуль с помощью require('node-tesseract'),
3. Обработка изображения
Использовать оболочку в Node.js довольно просто, она состоит из простого метода с именем process, Этот метод ожидает в качестве первого параметра абсолютный или относительный путь к файлу изображения для обработки, в качестве второго параметра — объект с конфигурацией (необязательно использовать настройки по умолчанию) и в качестве третьего параметра — обратный вызов, запускаемый по окончании команды.
Инициализация по умолчанию
Для обработки изображения требуется модуль node-tesseract и вызовите функцию процесса с двумя обязательными аргументами (имя файла и обратный вызов):
var tesseract = require('node-tesseract');
tesseract.process('image.jpeg', (err, text) => {
if(err){
return console.log("An error occured: ", err);
}
console.log("Recognized text:");
// the text variable contains the recognized text
console.log(text);
});Пользовательские параметры
Все свойства в объекте параметров являются теми же аргументами, которые вы используете с tesseract через командную строку, например команду tesseract image.jpeg output_filename -l eng+deu -psm 6 имеет 4 аргумента, однако первый аргумент задается вашим кодом, а второй — библиотекой, это означает, что -l а также -psm параметры должны быть заданы в объекте параметров:
var tesseract = require('node-tesseract');
var options = {
// Use the english and german languages
l: 'eng+deu',
// Use the segmentation mode #6 that assumes a single uniform block of text.
psm: 6
};
tesseract.process('image.jpeg', options , (err, text) => {
if(err){
return console.log("An error occured: ", err);
}
console.log("Recognized text:");
console.log(text);
});Известные вопросы
При использовании разных языков (и, возможно, огромных файлов), вы можете поймать следующее исключение при выполнении вашего скрипта:
Error :An error occured: { Error: stderr maxBuffer exceeded
at Socket. (child_process.js:278:14)
at emitOne (events.js:96:13)
at Socket.emit (events.js:188:7)
at readableAddChunk (_stream_readable.js:176:18)
at Socket.Readable.push (_stream_readable.js:134:10)
at Pipe.onread (net.js:548:20)Эта ошибка «превышено значение stderr maxBuffer» вызвана тем, что child_process.exec, используемый для обработки tesseract с помощью node.js, убивает процесс, поскольку допустимого объема данных стандартного вывода недостаточно (значение по умолчанию 200 КБ). Чтобы предотвратить эту ошибку, вам нужно использовать и установить maxBuffer свойство в параметрах процесса. node-tesseract позволит вам достичь этого, предоставив объект в env имущество:
var tesseract = require('node-tesseract');
var options = {
// Use the english and german languages
l: 'deu',
// Use the segmentation mode #6 that assumes a single uniform block of text.
psm: 6,
// Increase the allowed amount of data in stdout to 16MB (A little exaggerated)
env: {
maxBuffer: 4096 * 4096
}
};
tesseract.process('german.jpeg', options , (err, text) => {
if(err){
return console.log("An error occured: ", err);
}
console.log("Recognized text:");
console.log(text);
});Замечания: в соответствии с вашими потребностями увеличьте значение maxBuffer.
Наконец, мы рекомендуем вам прочитать документация по использованию Tesseract с командной строкой чтобы увидеть больше вариантов конфигурации.