Хавьер спрашивает:
Я писатель рассказов и сказок. Я ищу бесплатную программу оптического распознавания символов (OCR) или интеллектуального распознавания символов (ICR), чтобы сканировать мои старые рукописи из изображений или фотографий, чтобы я мог преобразовать их в файлы Microsoft Word.
Существуют ли бесплатные и точные программы, способные сделать это? К сожалению, у меня нет сканера, но у меня есть доступ к цифровой камере с разрешением 20 мегапикселей.
Я писатель рассказов и сказок. Я ищу бесплатную программу оптического распознавания символов (OCR) или интеллектуального распознавания символов (ICR), чтобы сканировать мои старые рукописи из изображений или фотографий, чтобы я мог преобразовать их в файлы Microsoft Word.
Существуют ли бесплатные и точные программы, способные сделать это? К сожалению, у меня нет сканера, но у меня есть доступ к цифровой камере с разрешением 20 мегапикселей.

Ответ Каннона:
Как вы уже упоминали, существует несколько видов технологий распознавания символов, которые могут автоматически преобразовывать рукописные или печатные надписи в цифровые символы. Уровень точности этих видов программного обеспечения сильно различается в разных реализациях. Некоторые конвертируют по буквам, а другие могут конвертировать целые слова. Существует три основных категории этого программного обеспечения:
- Оптическое распознавание символов (OCR)
- Интеллектуальное распознавание символов (ICR)
- Интеллектуальное распознавание слов (IWR)
Оптическое распознавание символов
По правде говоря, OCR — это общий термин, и часто все методы, описанные в этой статье, называются OCR — Википедия, однако, дает OCR свою собственную классификацию, но современные реализации, как правило, объединяют несколько методов. Так что же это делает? OCR преобразует отдельные печатные или рукописные буквы в цифровые символы. Таким образом, программа просматривает документ, а затем пытается преобразовать его в простой текст, угадывая, что представляет собой каждый символ.
Программное обеспечение не идеально. Программное обеспечение OCR может неправильно истолковывать отдельные символы с похожим внешним видом, что приводит к ошибочным словам и неточным выводам. В большинстве случаев пользователи могут копировать текст, сгенерированный программой OCR, в текстовый процессор и автоматически исправлять орфографические ошибки. Часто ошибки будут отображаться в виде похожих символов. Например, буква «d» может быть представлена как «cl».
Но когда дело доходит до рукописных текстов, распознавание текста не очень хорошо. По крайней мере, большинство бесплатных реализаций трагически плохи. Есть некоторые коммерческие продукты, которые действительно могут записать рукописную транскрипцию, но их цена делает их полностью недоступными для широкой публики. Например, есть программное обеспечение Lexmark для чтения оптических дисков ReadSoft. Это корпоративное программное обеспечение стоит тысячи долларов.

Интеллектуальное распознавание символов
ICR — это подмножество OCR, которое специализируется на преобразовании рукописного текста в отдельные цифровые символы. Учитывая, что ваши заметки и рукописи написаны от руки, наиболее полезной является программа ICR. Однако я не уверен, насколько точно они могут конвертировать тексты, написанные на иностранных языках, таких как испанский. Как и в случае с OCR, пользователи могут улучшить качество выводимых текстов, скопировав их в текстовый процессор с включенной корректировкой орфографии, а затем отредактировав вручную.

Интеллектуальное распознавание слов
Последней эволюцией OCR и ICR является программное обеспечение Intelligent Word Recognition. Вместо того, чтобы распознавать отдельные символы, он пытается перевести все рукописные слова. Как и OCR и ICR, интеллектуальное распознавание слов часто неправильно переводит слова и требует, чтобы пользователь вручную исправлял любые допущенные ошибки.
Что такое лучшее бесплатное программное обеспечение для распознавания текста?
Тессеракт
Есть много доступных вариантов. Тессеракт, вероятно, лучшее программное обеспечение для оптического распознавания текста с открытым исходным кодом. Насколько мне известно, он смотрит только на отдельных персонажей, а не на целые слова.
Потому что вы используете Microsoft Word (который имеет лучшую, наиболее настраиваемую проверку орфографии
в бизнесе), вы можете просто скопировать весь текст в Word, а затем запустить проверку орфографии, чтобы убрать орфографические ошибки.
Тессеракт на самом деле является механизмом OCR, который запускается из командной строки. Если вы не готовы справиться с трудностями владения инструментом командной строки, вы, вероятно, захотите установить что-то более удобное для пользователя. Существует загружаемый «интерфейс» (или графический пользовательский интерфейс), который позволяет использовать Tesseract в качестве инструмента перетаскивания: PDF OCR X. Сначала установите пакет программного обеспечения, а затем запустите его. Вы увидите окно:
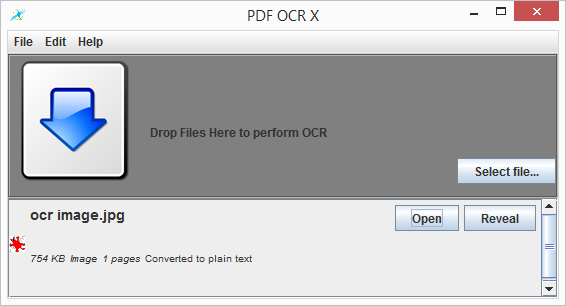
Затем вы просто перетащите файл изображения в окно. Как только изображение загрузится, запустите программу транскрипции OCR. Это может занять минуту или около того.
К сожалению, он оказался совершенно неадекватным для обработки вашего текста. Вот как это выглядит после извлечения текста из документа:
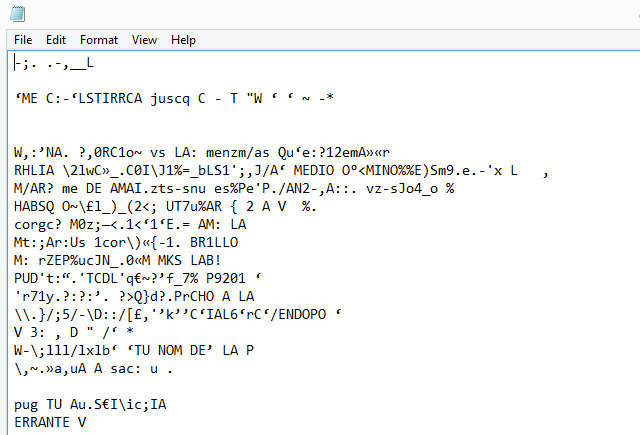
Microsoft OneNote
Поскольку, похоже, вы уже используете Microsoft Office, возможно, лучшим вариантом также является Microsoft. Я предполагаю, что у вас есть копия Microsoft Office, в которую входит OneNote. Это оснащено довольно продвинутой технологией OCR.
Кроме того, как на iOS, так и на Android имеется также совершенно бесплатный объектив Microsoft Office, который может конвертировать JPEG (и другие форматы изображений) непосредственно в текст. Что делает мобильные версии такими замечательными, так это то, что вы можете снимать изображения, загружать их в систему облачных вычислений Microsoft, а затем запускать извлечение текста из OneNote на рабочем столе.
Процесс довольно прост. Сначала сфотографируй свой текст. Если вы решили использовать приложение OneNote, вам нужно всего лишь сохранить файл в своей учетной записи OneDrive. В противном случае перенесите изображение на свой компьютер и перетащите на OneNote.
Затем щелкните правой кнопкой мыши на изображение и выберите копия Текст с картинки из контекстного меню.
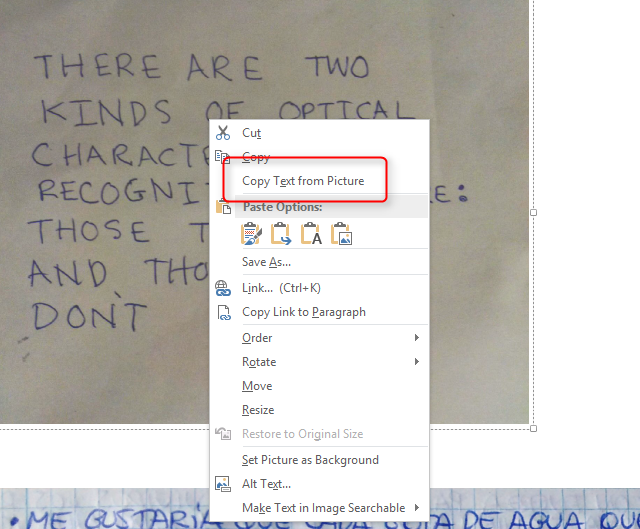
Затем щелкните правой кнопкой мыши пустую часть OneNote (или в приложении для чтения текста) и вставьте текст в. Вывод текста из вашего документа выглядит следующим образом:

К сожалению, результаты OneNote не дают ничего хорошего, создавая полную чушь. Это может быть вызвано сочетанием таких факторов, как искаженное изображение или запись, которые не выполняются по прямой линии, или просто потому, что программное обеспечение недостаточно хорошее.
Google Keep
На данный момент лучшее решение для распознавания рукописных документов относится к машинному обучению: в частности, глубокому обучению. Глубокое обучение — это сложный метод обучения компьютера выполнению задач, в которых раньше только человек преуспел, таких как распознавание лиц (Picasa распознает лица
, хочешь верь, хочешь нет). Google недавно приобрел DeepMind, который разрабатывает технологию глубокого обучения
, Это приобретение ключа имело большой эффект: Microsoft проигрывает Google в OCR
, Сейчас Google предлагает один из самых продвинутых (и бесплатных) методов: Google Keep.
Google Keep (который мы впервые рассмотрели в 2013 году
) также предлагает мобильную версию своего приложения для Android. Как и в OneNote, вы можете снимать изображения и передавать их прямо в облако Google. Просто перетащите изображение в окно Google Keep. Затем нажмите на кнопку меню (три вертикальные точки) и выберите Захватить текст изображения из контекстного меню.
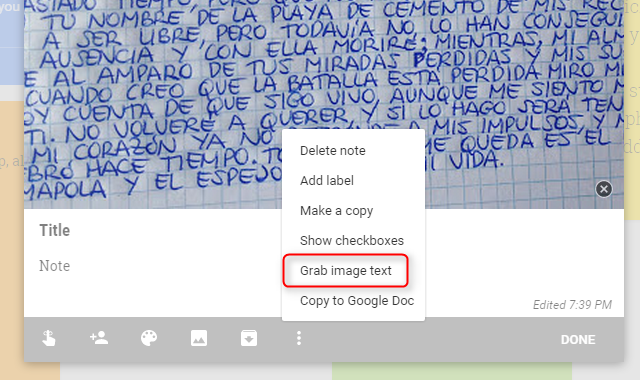
Вот как это выглядит после извлечения текста:

Google Keep Wins
Как видите, Google Keep доминирует в конкурентной борьбе. Результаты могут быть еще более улучшены с помощью инструмента для редактирования изображений
увеличить контраст и выровнять изображение.
Надеюсь, эти варианты помогут. Если вам нужны дополнительные параметры распознавания текста, ознакомьтесь с 5 лучшими инструментами распознавания текста
, для дополнительной информации.




